(Fixing) Determinism in Robotics Testing
Kyle Franz
Sep 02, 2024Here at Basis, we’re building a production/testing focused robotics framework. Along those lines, determinism when testing is one of our primary goals. This article is focused on how basis can not only achieve determinism in tests, but use it to run your tests lightning fast.
Here’s a preview:
replay |
deterministic_replay |
|---|---|
 |
 |
Background
Determinism in robotics is an ongoing problem, both for runtime and for testing. This post aims to show a solution for testing/simulation.
The big issues come down to this:
- ROS (and other robotics frameworks) don’t have any way of running deterministically, even in testing mode.
- Code running at different speeds between the robot and your development workstation is a problem
- Code running at a different speed in CI and on the robot is a huge problem, made worse by either cheapening out on CI hardware or running with too much parallelism in an effort to speed up test times.
- At a low level, running the same code on the same system will behave differently due to transport layer and scheduling nondeterminism.
As a result of the above, making integration tests for robots sucks, and the tooling that does exist kinda sucks as well. An integration test running in CI might look like this:
- Launch some process orchestrator (ROS Master, etc)
- Launch some subset of your robot with a custom launch file
- if you’re lucky, someone’s added a test flag to your main launch file
- if you’re unlucky, there’s a separate launch file for tests that might be out of date to what your robot actually runs
- Replay some recorded data at a slower than realtime speed to try and dodge transport/scheduling nondeterminism
- Wait extra long because you’re running at slower than realtime speed.
- Your test fails CI.
- Cross fingers that the cleanup for the test actually kills all the processes the test launched.
- Go repeat the above on your development desktop.
- The test succeeds (or maybe randomnly doesn’t succeed).
- Rerun the test in CI, waiting even longer.
- The test succeeds.
- Throw your hands up in the air, give up, and merge your code, blaming the simulation team if it fails again in
main.
In the end, this just trains the engineering team to ignore test results, and discourages creating larger/more complex tests and simulations. When a test fails, is it due to the framework or due to the actual robotics code? Especially in safety critical environments, it’s important to rule out flakes.
Basis is aiming for tests to give the same result, every time. Other types of determinism will also come later (code running the same time on replay as it did at runtime, for example).
Sources of nondeterminism
Nondeterminism can come from a wide variety of sources.
The current main focus of efforts creating basis (and the focus of this blog post) is nondeterminism from the transport layer and scheduling related nondeterminism.
Nondeterminism at the transport layer includes nondeterminism in the network stack, the order sockets are processed in, what happens when two messages come in at the same moment, that sort of thing.
Scheduling nondeterminism encompasses threading related woes, performance differences between test executions, etc.
A non-exhaustive list of other sources of nondeterminism:
- calls to random()
- use of the system clock
- use of networked resources
- data races
- compiler flags
- cosmic rays
- pointer comparisons
(I’ve seen all of these in test environements before.)
How can we fix this?
A few rules:
- All code to be run deterministically happens in response to a message or a timer (in basis terms, everything lives inside Handlers)
- No side channel communication between Handlers. Use a topic - Basis supports runtime only topics (raw C++ structs), so use them.
- This isn’t strictly true - Handlers in the same Unit will share a C++ class, setting a variable is a side channel. This is mostly an issue with complex Units that allow parallel execution of Handlers. We will (eventually) provide tools to help with this case.
- (Along with 2) Robotics code doesn’t know about what a Subscriber or Publisher are. They take messages on topics as inputs and output messages on topics as outputs.
- This doesn’t stop tooling that does care about these concepts, it just means those tools can’t be run deterministically as part of a test.
- This does mean that externally triggered code (sensor drivers) won’t be determinisitic, but that’s not a problem for most tests.
- All Handlers have associated metadata describing their inputs, outputs, execution conditions.
- All Units (think: ROS Node) can be loaded dynamically and contain the metadata
- Code inside Handlers is determinisitic (duh).
From these rules, one can build a scheduler that looks at the requested Units to be run, looks at the contents of any data to be replayed, and appropriately invokes each Handler in the correct (and deterministic) order, with the correct data. Basis is built from the ground up to support this use case.
Demonstration
Let’s show how basis can help with determinism. First we’ll record some data from a live run. Then we’ll run a replay test on that data and find issues with the testing process. Finally, we’ll show deterministic_replay at work, fixing those issues.
Recording some data
Here’s an example of a basis Unit that wants to do some work. This Unit will take in a single message, block for 100ms (doing fake “work”) and then exit, allowing other callbacks to run.
threading_model:
single
cpp_includes:
- simple_pub_sub.pb.h
handlers:
OnChatter:
sync:
type: all
inputs:
/chatter:
type: protobuf:StringMessage
OnChatter::Output simple_sub::OnChatter(const OnChatter::Input &input) {
// Convert protobuf nanoseconds into a basis timestamp
auto send_stamp = basis::core::MonotonicTime::FromNanoseconds(input.chatter->send_stamp());
BASIS_LOG_INFO("OnChatter: {} {}", input.chatter->message(), send_stamp.ToSeconds());
// Calculate delay between "now" and when the message was sent
basis::core::Duration delay = input.time - send_stamp;
if (delay > basis::core::Duration::FromSeconds(0.2)) {
BASIS_LOG_WARN("/chatter delayed by {:.2f}s - queueing has occured", delay.ToSeconds());
}
constexpr int work_time_ms = 2000;
BASIS_LOG_INFO("Doing {} ms worth of work", work_time_ms);
std::this_thread::sleep_for(std::chrono::milliseconds(work_time_ms));
return OnChatter::Output();
}
Running this unit along with another unit to produce on /chatter at 1Hz will give a console output resembling this
[124998.122650826] [launch] [info] Recording (async) to /tmp/demo_124998.122377076.mcap
[124998.126956742] [launch] [info] Running process with 2 units
[124998.130765492] [launch] [info] Started thread with unit /opt/basis/unit/simple_sub.unit.so
[124998.134928909] [launch] [info] Started thread with unit /opt/basis/unit/simple_pub.unit.so
[124999.137999076] [/simple_pub] [info] PublishAt1Hz
[124999.138074076] [/simple_sub] [info] OnChatter: Hello, world! 124999.138065618
[124999.138080410] [/simple_sub] [info] Doing 100 ms worth of work
[125000.136988785] [/simple_pub] [info] PublishAt1Hz
[125000.137143077] [/simple_sub] [info] OnChatter: Hello, world! 125000.137124493
[125000.137151452] [/simple_sub] [info] Doing 100 ms worth of work
[125001.136178202] [/simple_pub] [info] PublishAt1Hz
[125001.136319869] [/simple_sub] [info] OnChatter: Hello, world! 125001.136305744
[125001.136327452] [/simple_sub] [info] Doing 100 ms worth of work
[125002.137870703] [/simple_pub] [info] PublishAt1Hz
[125002.138054536] [/simple_sub] [info] OnChatter: Hello, world! 125002.137991619
...
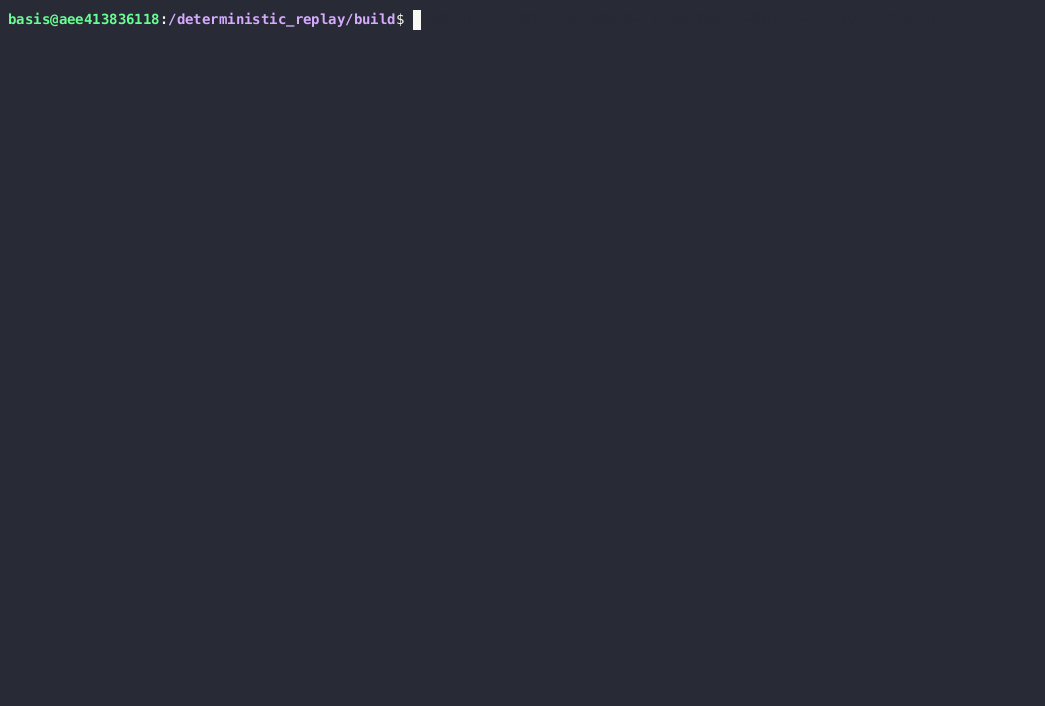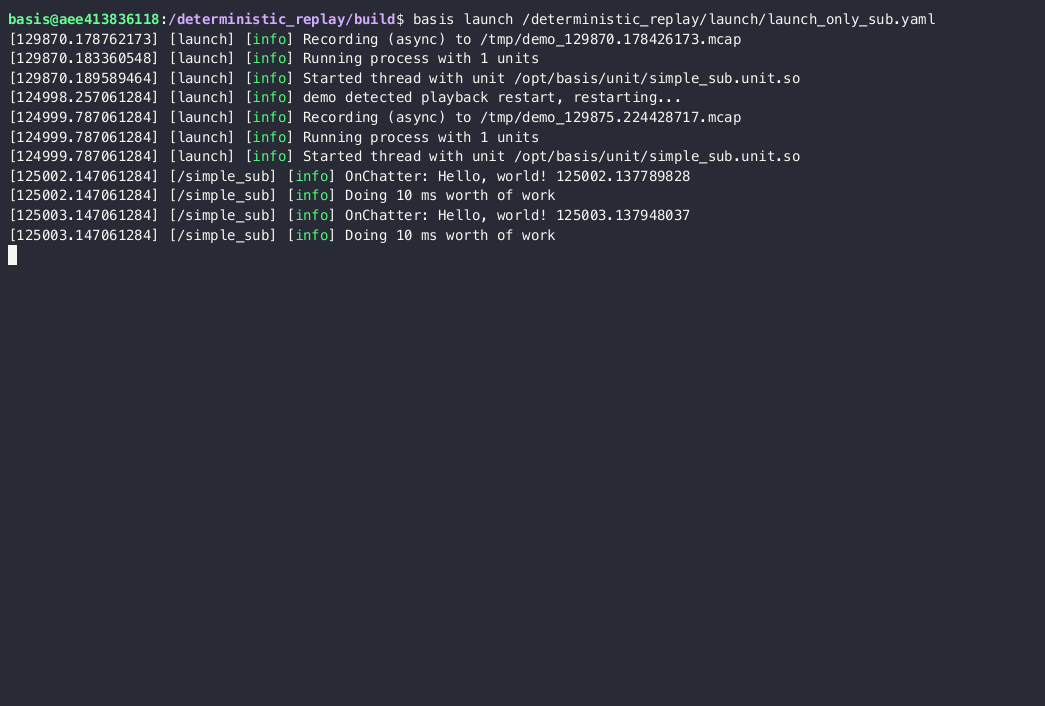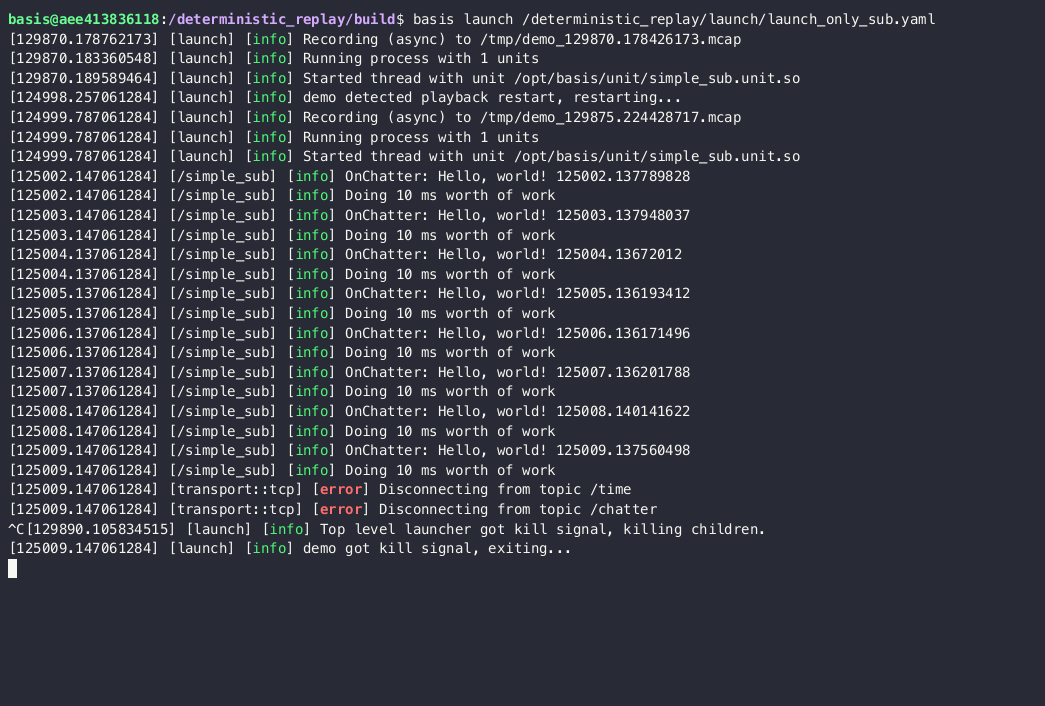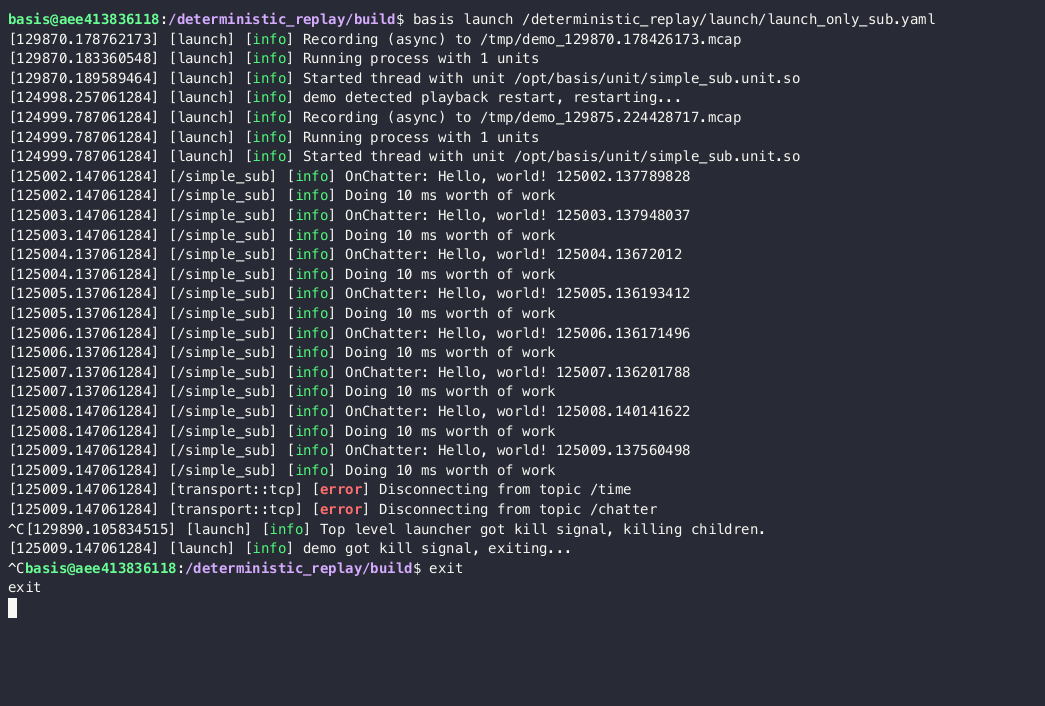
Replaying the data
Great, but now let’s pretend this was data recorded on a robot. We might want to run replay /tmp/demo_124998.122377076.mcap, along with simple_sub. If the hardware is similar between the two environments, we might see something like this:
[125458.039238910] [launch] [info] Running process with 1 units
[125458.040486243] [launch] [info] Started thread with unit /opt/basis/unit/simple_sub.unit.so
[124998.307061284] [launch] [info] simple_sub detected playback restart, restarting...
(note the time jump here, we got a new simulated time step)
[124998.977061284] [launch] [info] Running process with 1 units
[124998.977061284] [launch] [info] Started thread with unit /opt/basis/unit/simple_sub.unit.so
[125001.137061284] [/simple_sub] [info] OnChatter: Hello, world! 125001.137061284
[125001.137061284] [/simple_sub] [info] Doing 100 ms worth of work
[125002.147061284] [/simple_sub] [info] OnChatter: Hello, world! 125002.147061284
[125002.147061284] [/simple_sub] [info] Doing 100 ms worth of work
[125003.147061284] [/simple_sub] [info] OnChatter: Hello, world! 125003.147061284
[125003.147061284] [/simple_sub] [info] Doing 100 ms worth of work
...
Problem 1 - missing data, nondeterminism.
Rerunning this a few times, we see Problem #1 - we sometimes miss the first message of the test, and get an output:
[125002.147061284] [/simple_sub] [info] OnChatter: Hello, world! 125002.147061284
A quick check with mcap-cli reveals…
basis@aee413836118:/basis/demos/simple_pub_sub/build$ ~/mcap-linux-arm64 cat --json /tmp/demo_124998.122377076.mcap --topics /chatter
{"topic":"/chatter","sequence":0,"log_time":124999.138044993,"publish_time":124999.138044993,"data":{"sendStamp":"124999137959660", "message":"Hello, world!"}}
{"topic":"/chatter","sequence":0,"log_time":125000.137092327,"publish_time":125000.137092327,"data":{"sendStamp":"125000136919993", "message":"Hello, world!"}}
{"topic":"/chatter","sequence":0,"log_time":125001.136257244,"publish_time":125001.136257244,"data":{"sendStamp":"125001136105286", "message":"Hello, world!"}}
...
Several messages are missing from the test. Even our most complete replay was missing 124999 and 125000.
Problem 2 - performance differences can mean nondeterminism
Now what if instead, our testing environment was slower (overloaded CI, different/no GPU, less cores). In this scenario, let’s pretend that the work takes 2000 ms to run, and set constexpr int work_time_ms = 2000;.
Let’s run that same replay test.
[125002.147061284] [/simple_sub] [info] OnChatter: Hello, world! 125002.137789828
[125002.147061284] [/simple_sub] [info] Doing 2000 ms worth of work
[125004.147061284] [/simple_sub] [info] OnChatter: Hello, world! 125003.137948037
[125004.147061284] [/simple_sub] [warning] /chatter delayed by 1.01s - queueing has occured
[125004.147061284] [/simple_sub] [info] Doing 2000 ms worth of work
[125006.147061284] [/simple_sub] [info] OnChatter: Hello, world! 125004.13672012
[125006.147061284] [/simple_sub] [warning] /chatter delayed by 2.01s - queueing has occured
[125006.147061284] [/simple_sub] [info] Doing 2000 ms worth of work
[125008.147061284] [/simple_sub] [info] OnChatter: Hello, world! 125005.136193412
[125008.147061284] [/simple_sub] [warning] /chatter delayed by 3.01s - queueing has occured
[125008.147061284] [/simple_sub] [info] Doing 2000 ms worth of work
Look at that - rather than the second message being processed at 125003.137948037, it’s processed at 125004.147061284, a second later than expected (or exactly as one would expect for adding an additional second of blocking…). The delay will only continue to go up, and the queues backing the pub/sub system generally won’t be configured for infinite space, resulting in dropped messages and incorrect timings.
If the original runtime looked like this:

(Apologies for the default LucidChart colorscheme)
With our artifical slowdown, it now looks like this:

Note the queueing - we can’t process more messages while OnChatter is executing, but the replay system doesn’t know this and keeps publishing messages.
Problem 3 - integration tests are slow, clunky, and don’t pair well with unit testing frameworks
If each message takes 100ms to process, and we replay 10 messages, how long would you expect this test to take? With a regular integration test: 10 seconds, for 1 second worth of work.
Let’s say our CI hardware is even faster, able to process a message in 10ms - the test still takes 10 seconds to run, for 100ms worth of work.
Along with this, how would we integrate this test with gtest? We’d have to build some sort of framework that manages forking or shelling out to launch each part of it, with timeouts, management for grandchildren processes, etc.
If we wanted to programmatically create messages (avoiding the use of serialized data on disk), or create a single message and check the output of the system after each step, how would we do it? With ROS you’d have two choices:
- Stand up a ROS Master, launch the nodes you care about, initialize your test as a ROS node, publish the message, and spin until you (maybe) get a response. (Don’t forget to turn off paralellism for your tests!)
- Break apart your ROS Nodes into libraries, manually shuffling messages between the business logic for each node (good luck keeping this in sync with the launch files)
The solution
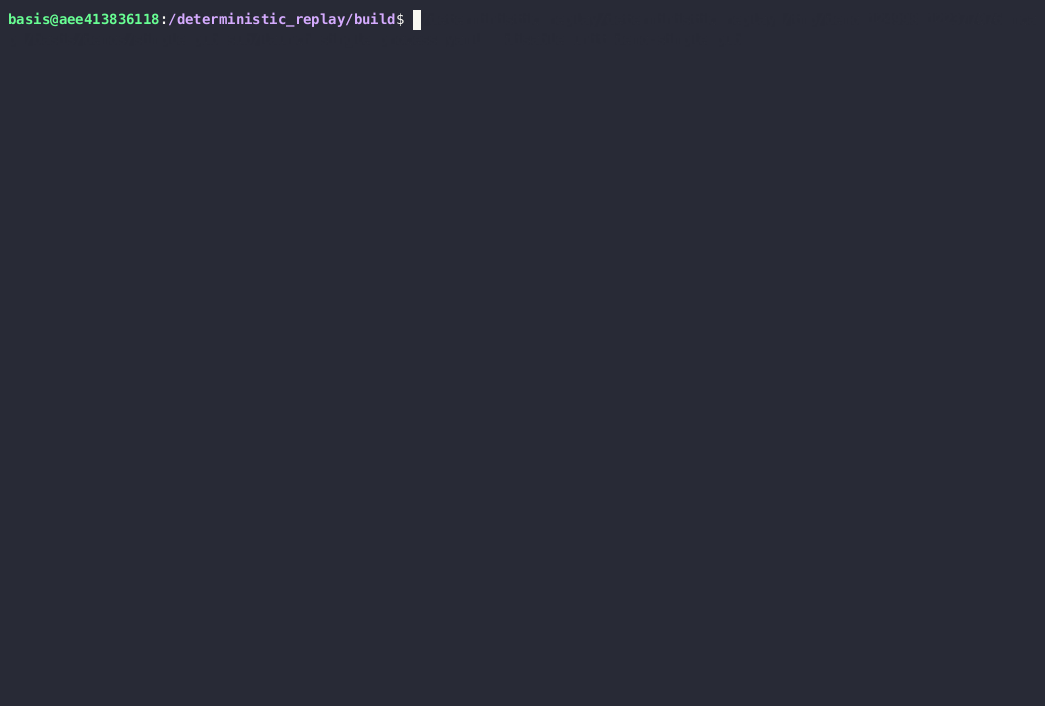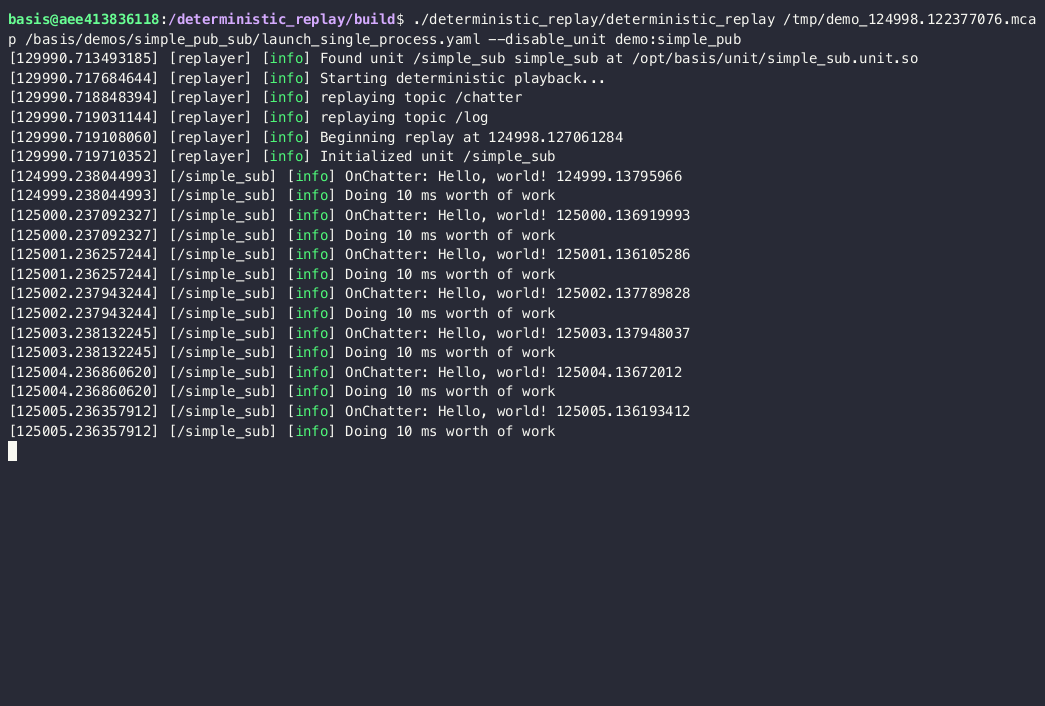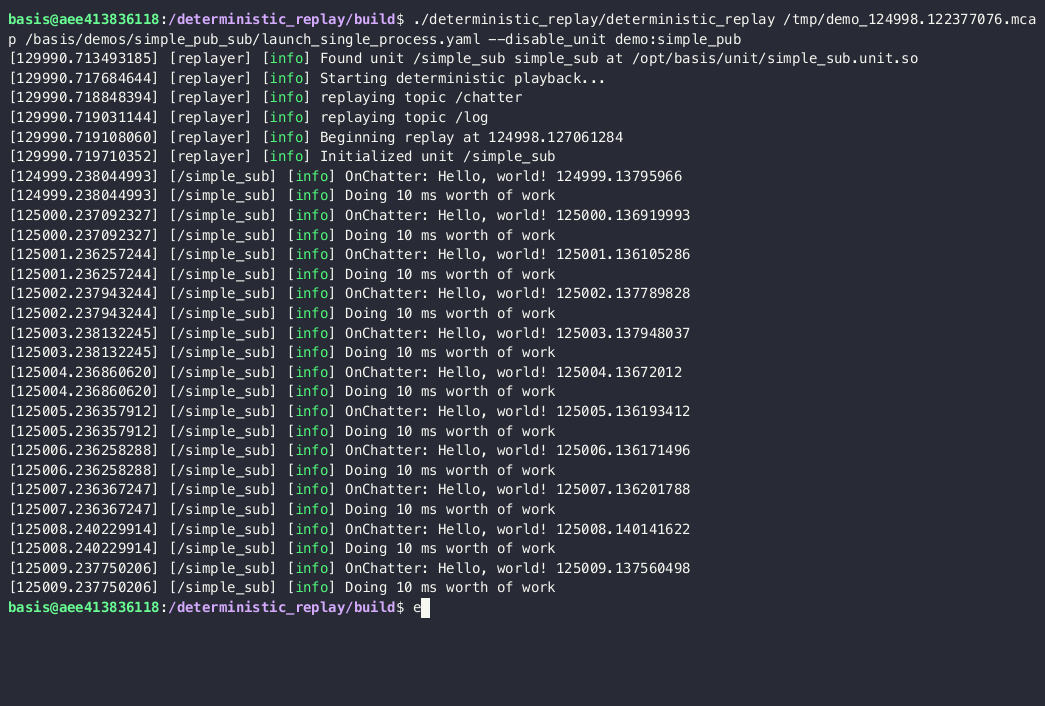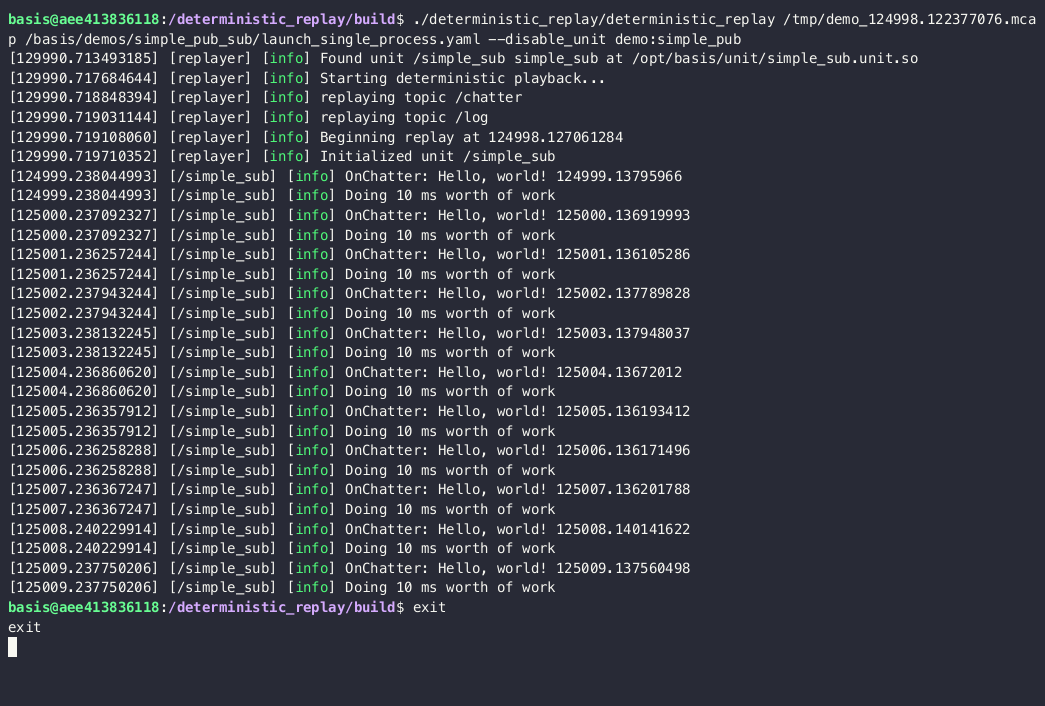
Let’s rerun this with basis’s deterministic replayer.
deterministic_replay /tmp/demo_124998.122377076.mcap /basis/demos/simple_pub_sub/launch_single_process.yaml --disable_unit demo:simple_pub
[129000.980036858] [replayer] [info] Found unit /simple_sub simple_sub at /opt/basis/unit/simple_sub.unit.so
[129000.982984441] [replayer] [info] Starting deterministic playback...
[129000.984189191] [replayer] [info] replaying topic /chatter
[129000.984319524] [replayer] [info] replaying topic /log
[129000.984376316] [replayer] [info] Beginning replay at 124998.127061284
[129000.985144524] [replayer] [info] Initialized unit /simple_sub
[124999.238044993] [/simple_sub] [info] OnChatter: Hello, world! 124999.13795966
[124999.238044993] [/simple_sub] [info] Doing 2000 ms worth of work
[125000.237092327] [/simple_sub] [info] OnChatter: Hello, world! 125000.136919993
[125000.237092327] [/simple_sub] [info] Doing 2000 ms worth of work
[125001.236257244] [/simple_sub] [info] OnChatter: Hello, world! 125001.136105286
Beautiful - we even caught the first few messages that were dropped before. The scheduler now waits on Handlers that are expected to be complete (in terms of simulated time) but aren’t yet finished (in realtime).

We can see that we don’t do any more work (such as replaying messages) while OnChatter is executing, as the Handler is only supposed to take 100ms of simulation time. It sucks that we’re running twice as slow as realtime, but it’s better than running with inaccurate messages.
Problem 1, Problem 2 - solved.
As for Problem 3… remember that preview gif from the beginning of the article?
Let’s turn the work time all the way down to 10ms. Because deterministic_replay knows when code should run, it also knows when code isn’t running. We can run the code as fast as our CPU will let us, ignoring the fact that the replay data publishes at 1Hz. This enables integration tests that run lightning fast.
(Other data replay systems usually have some form of rate multiplier command - but this is tough to tune for all conditions).
replay |
deterministic_replay |
|---|---|
|
|
Everything can be run in a single process for test mode, meaning a coordinator (master) process is only needed if communication with visualizers or other tooling is required (not required for unit testing). One could link deterministic_replay into a unit test, then run a launch file (or even a programatically created list of Units), push in messages, query outputted messages and inner states of nodes, modify in flight messages, etc. No extra processes needed.
Even further
With this power, we can do more:
- Find out what happens if one of our messages arrives later than expected, or test different timing related error paths. How well have you actually tested your degraded states around timing?
- The default behavior of
deterministic_replayis to always rerun events that happen at the same time in the same order. What if instead we reversed it? Or randomized it with a seed? With message send time jitter randomization added on top, one could long tail test for timing related bugs. - Test out “what if” situations that may be expensive to implement. Let’s say your Perception Lead says he can speed up the perception stack by 15% with a quarter’s worth of work and two engineers. It sounds good on paper, but will a faster perception stack actually lead to better robot performance? Before doing the quarter’s worth of work, run your integration test suite with the promised timings, instead.
lldb -- deterministic_replayer ...just works, and can pause all units, properly, without having to mess with fork modes.
Hasn’t this been built yet?
This sort of tooling has been asked for before:
- Unanswered answers.ros.org post
- ROS1’s documentation: “For nodes like turtlesim, where minor timing changes in when command messages are processed can subtly alter behavior, the user should not expect perfectly mimicked behavior.”
- Various other ROS answers posts
- Engineers internal to companies integrating with Gazebo/Applied Intuition/internal tools/etc.
Various groups have tried approaching it:
- A cool deck on ROS runtime determinism from BOSCH (runtime determinism isn’t covered here, but basis does make this easier)
- Flow framework https://github.com/ZebraDevs/flow_ros?tab=readme-ov-file (This appears to be mostly a intermediary between ROS publishers and robotics business logic - I approve, good architecture. But where’s the deterministic replay?)
- ROS2 DEF - A bolt on system for ROS2 from Ulm University. A valiant effort, but abandoned and incomplete. Can’t fully work due to ROS2 architecture.
- Various large robotics companies having to implement this internally to various levels of completeness, using various strategies. Unfortunately these are going to be very company specific and they aren’t likely to publish or sell them.
Funnily enough, Applied Intuition completely sidesteps the issue, saying that determinism in ADAS is good, but not giving any answers for how to achieve it when integrating.